



Cómo empezar con Databricks (gratis)
guía rápida y sin complicaciones


📌 En este post te muestro cómo crear tu cuenta en Databricks Free Edition, explorar su interfaz y correr tu primer notebook usando el cluster serverless gratuito. Sin humo, sin tarjeta de crédito y 100% en español.
¿Qué es Databricks Free Edition?
Databricks Free Edition es una forma de explorar la plataforma de manera gratuita, ideal para quienes quieren experimentar con Spark, Delta Lake, notebooks colaborativos y workflows de MLOps sin necesidad de pagar.
💻 No necesitás tarjeta de crédito
☁️ Usás un cluster serverless que se crea solo para vos
🔁 Ideal para pruebas, formación y prototipado
Paso a paso para crear tu cuenta
Ingresá a: https://login.databricks.com/?intent=SIGN_UP&provider=DB_FREE_TIER
Registrate con email o cuenta de Google
Ingresa el código de verificación
Elige tu nombre de la cuenta (🔒 no se puede cambiar después)
Elegí tu región/pais
Debería estar orientado a tu zona geográfica; por ejemplo, yo vivo en Holanda y me conviene la región de West Europe (esto ayuda a Databricks a subir los recursos más cercanos a ti para un rendimiento óptimo).
Aguardá unos segundos y ¡listo! 🎉 Ya tenés acceso al entorno.

Primer vistazo a la UI de Databricks
Cuando entrás, vas a ver una interfaz dividida en la parte central que tiene un buscador estilo Google que en el futuro te va a ayudar a encontrar scripts .py o .sql, notebooks o tablas en Unity Catalog. Lo otro importante está en la parte izquierda en la barra lateral (aka. sidebar) con las herramientas y secciones que provee Databricks, pero no voy a ir en detalle uno por uno de todos (para las siguientes publicaciones 😉), mientras acá te dejo las más relevantes para empezar:
🔍 Workspace: El Workspace es esencialmente tu área principal de trabajo en Databricks. El Workspace te permite organizar tus notebooks en carpetas, facilitando la gestión de proyectos grandes (por ejemplo yo en el trabajo 🏦).

📁 Repos: Esta sección te permite conectar tu espacio de trabajo de Databricks con tus repositorios de GitHub. De esta manera, puedes sincronizar notebooks y código entre tu entorno de desarrollo local y Databricks.
🔄 Workflows: Los Workflows en Databricks te permiten automatizar ETLs y otras tareas repetitivas (aka. pipelines ). Puedes programar notebooks para que se ejecuten en momentos específicos o activarlos basándote en eventos (aka. event triggered).
🧪 Experiments: Esta característica está estrechamente vinculada con MLflow, una plataforma de código abierto para gestionar el ciclo de vida de modelos de Machine Learning y GenAI. Te permite realizar un seguimiento de los experimentos, registrar parámetros y comparar resultados.
⚙️ Compute: En la sección Compute, puedes gestionar los recursos computacionales disponibles para ti en Databricks. Esto incluye la creación, configuración y monitoreo de clusters.
Puedes crear diferentes tipos de clusters optimizados para diversas cargas de trabajo, como ingeniería de datos, aprendizaje automático o análisis de datos. Presten atención a que actualmente hay un bug 🐛 en Databricks Free Edition que te redirige a una nueva sección llamada (hace un mes no existia) SQL Warehouses 🏠. Pero importante para el siguiente capítulo porque ahora vamos a usar el cluster que Databricks nos provee gratuitamente, con el nombre Serverless Starter Warehouse.
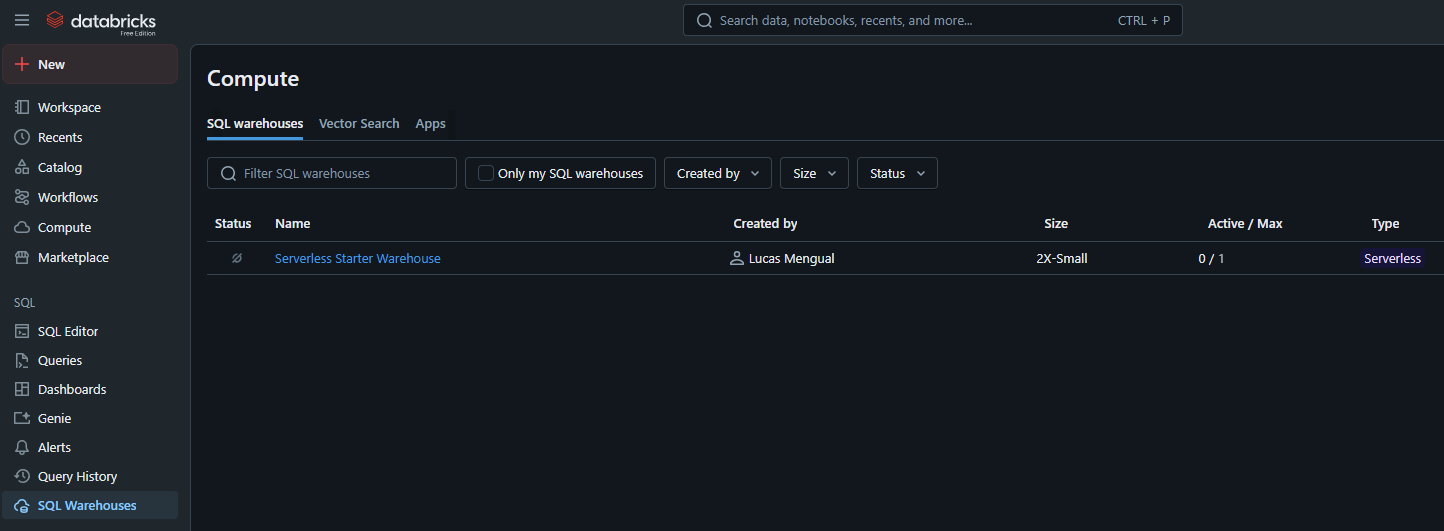


¿Qué puedo hacer con el cluster gratuito?
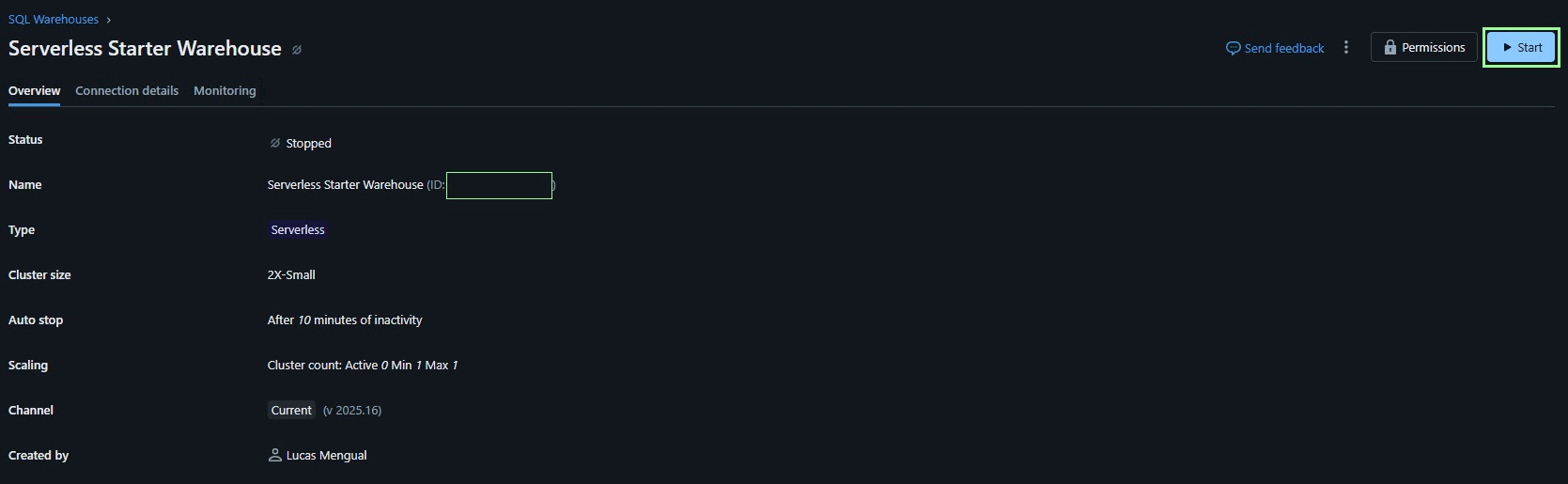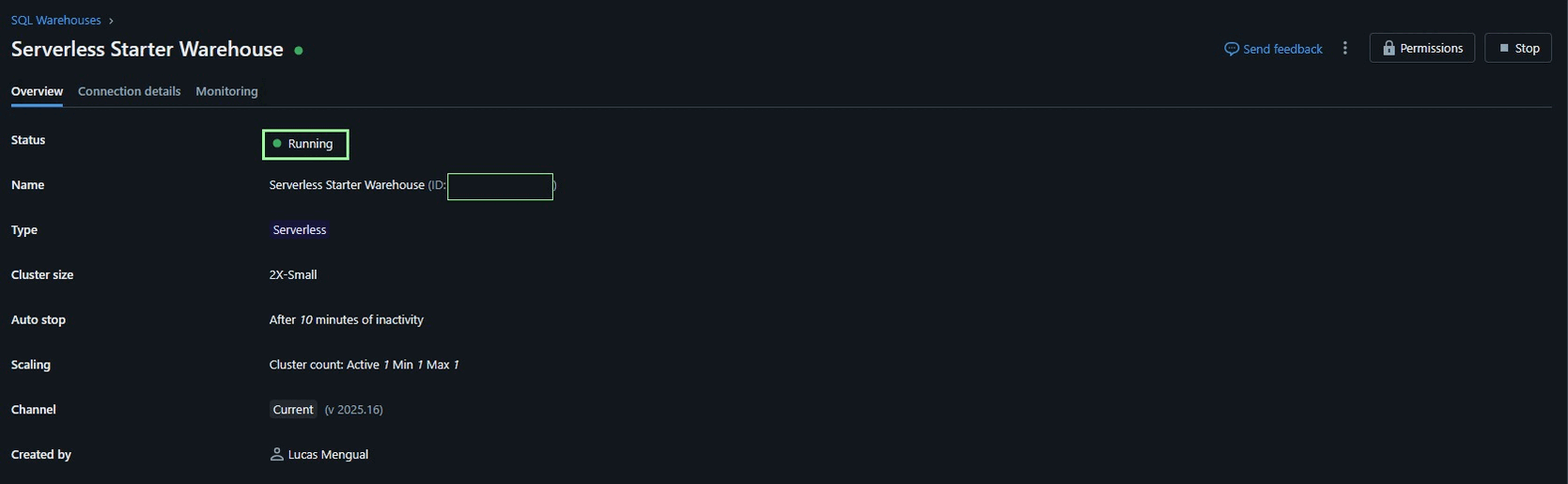
Si hacemos clic en Serverless Starter Warehouse, vamos a ver una página con la información del clúster. Y ahora clic en el botón arriba a la derecha en Start. Veremos que la parte de Status cambia a “Starting”, y en un par de segundos cambiará a “Running” y listo! 👍 El clúster estaría encendido.
En este caso, se trata de un clúster de SQL Warehouse con ventajas como un tiempo de ejecución de segundos, y es útil para análisis en SQL de tablas dimensionales, por ejemplo.
Aparte de esto, Databricks te da acceso a un clúster SQL serverless con recursos limitados pero más que suficientes para:
Consultas en SQL
Notebooks en Python, Scala o R
Prototipos con Spark
Pruebas de ML con MLflow
Vamos con un ejemplo: SQL Editor
Vamos a subir el ritmo un poco, y para mostrarles un caso de uso real, vamos a hacer una breve consulta en SQL. Primero, hagan clic en la pestaña SQL Editor en la barra lateral, y allí se abrirá una especie de editor para realizar consultas (aka. queries).
Copien la siguiente query y clic en Run para ejecutarlo:
select * from samples.nyctaxi.trips limit 100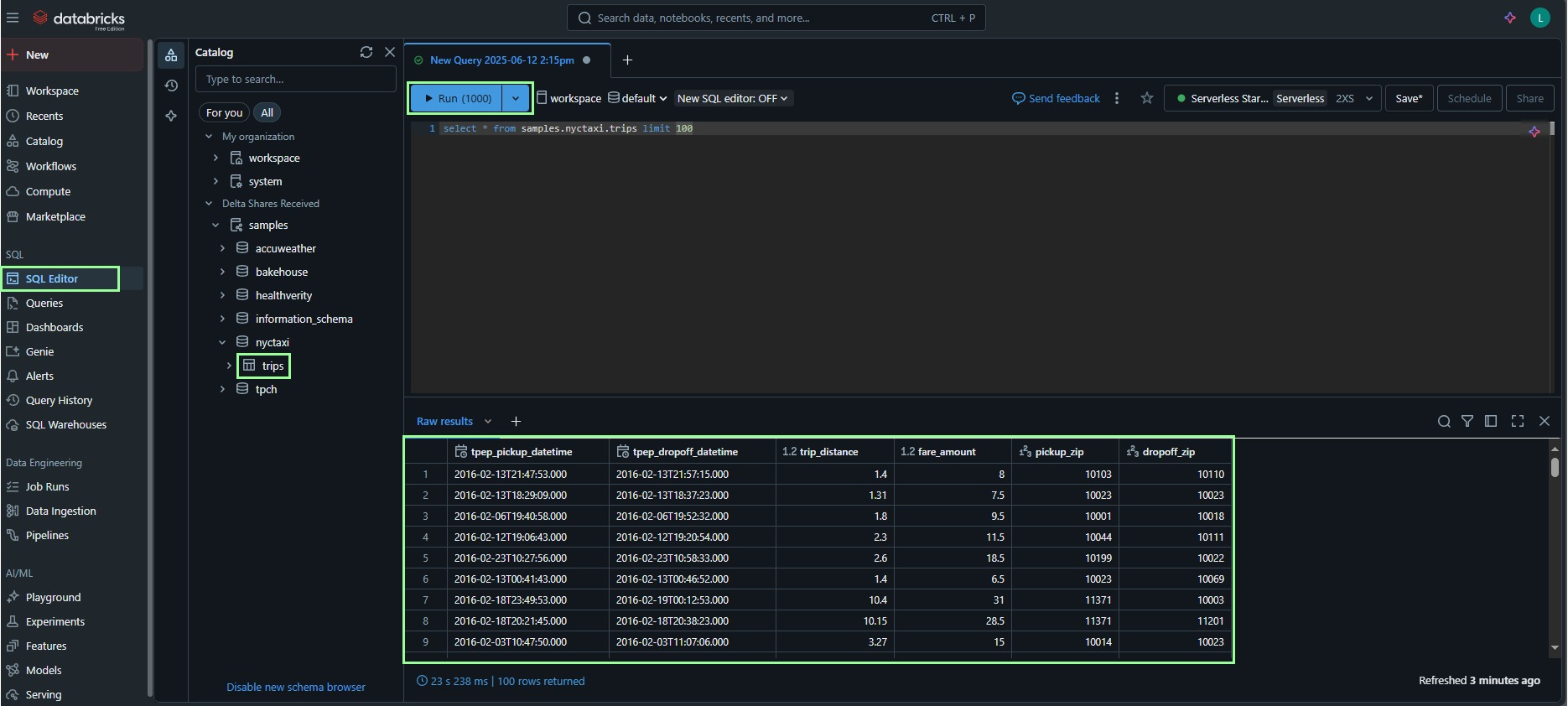
Vemos el output de de la query para la tabla de trips, del schema nyctaxi (del famoso dataset de Kaggle 🚕), del catalog samples. En la publicación de Unity Catalog 101 explico un poco más acerca de eso, y sobre todo de Data Governance…
¿Y ahora qué?
Proximamente voy a compartir:
Unity Catalog 101
Cómo conectar Databricks con fuentes externas
Delta Sharing desde cero
Cómo usar MLflow desde cero
Y cómo llevar estos notebooks a producción
Si te gusto mi 1ra publicación, dejame tu voto anonimo:
📬 Conectá conmigo: